Stability AI, the company behind the text-to-image service Stable Diffusion, has now released a generative AI service that can generate music snippets from text. With Stable Audio, users can feed the AI with text describing how they want the music to sound, resulting in a music snippet of 20 or 90 seconds.
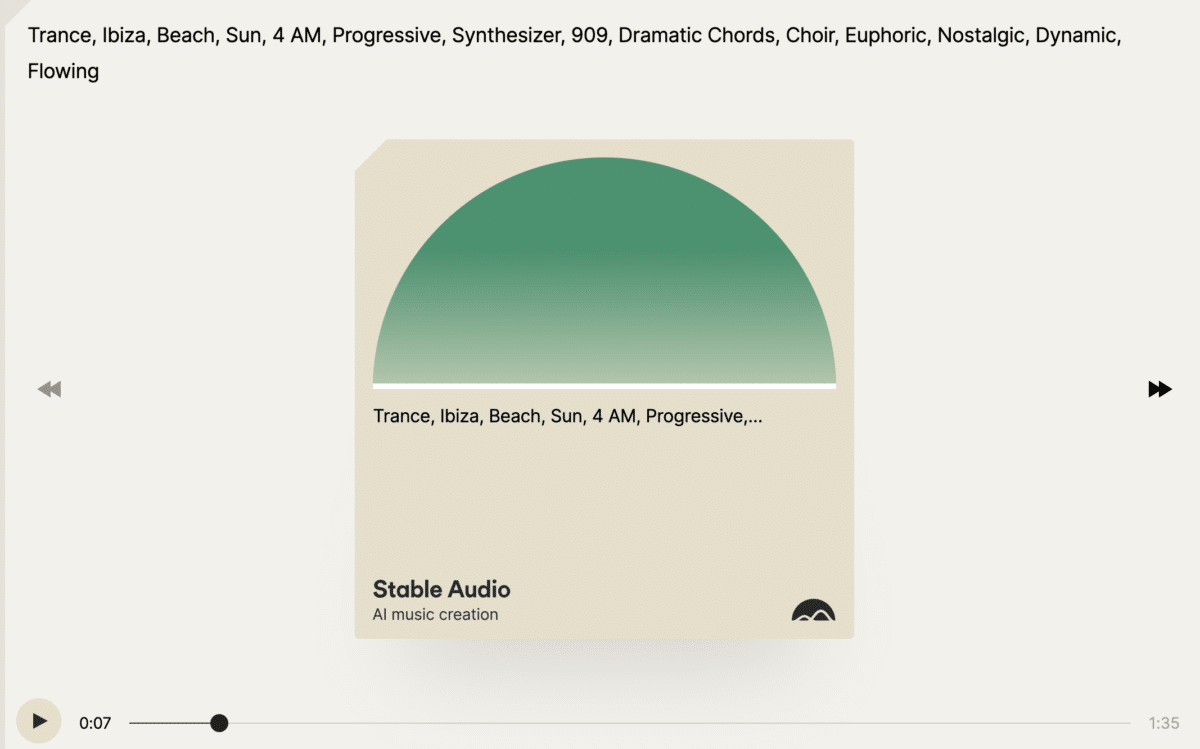
The service is trained on 800,000 music pieces from the AudioSparks audio library. However, it has not been trained to imitate music from specific artists, so it cannot be asked to create a music snippet resembling something The Beatles could have composed, as reported by Venture Beat.
Stable Audio is available in a free version where users can generate 20 music snippets of 20 seconds each per month. There is also a pro version priced at $12 per month, allowing users to generate 500 music snippets of 90 seconds each per month.